Note: I’ve been active as my professional alter-ego on Humanities Commons, where a colleague and I have set up a group for scholars interested in the history of medicine in the Middle East and North Africa, which is what I do professionally.
We’ve set up a shared Zotero group–join and contribute your entries, and let’s create a shared bibliography detailing the history of medicine in the Middle East and North Africa!
I have several posts envisioned detailed how to plan your research year, and I’ve decided to start with a couple of posts about what to do before you even leave home or set foot in your first archive.
(Full disclosure: This series will primarily discuss doing archival research; although what I say will be somewhat useful if you do oral history or other kinds of fieldwork, I won’t be targeting those specifically because I have pretty much no experience with them myself).
I’m writing these in no particular order and, in fact, I’m starting with workflow because a couple of friends are already working through this and I thought it would be most useful to them if I started here.
So.
What is a workflow, and why do you need to plan one?
Simply put, a workflow is how you go from this:
to this:
It’s a bit difficult to see, but the PDF of the document in the top photo with the blue cover is digitally attached to the entry highlighted in the screenshot on the bottom.
(For the record, the top photo was taken at the British National Archives in Kew).
Now, you may be asking yourself: yes, but why do I have to figure this out in advance?
The most important reason to have a workflow figured out is this: you need to determine how you’re going to get those thousands of pages you find in an archive into a usable format and bring them home with you.
1. Photocopying is expensive. Even if it’s just 7 cents a page, if you wind up photocopying a thousand pages (which is *incredibly easy to do*), you’re going to spend some serious bank. Photocopies are also heavy and take up space in your luggage. And then, of course, there’s the question of what happens if they get wet, dropped, spilled, stolen (along with the rest of your luggage), torn, burnt, etc.
2. Photocopying takes time. A number of archives do not have self-service photocopy machines; they have copying services which will do it for you. This comes at both a monetary cost and a time cost, because unless the copyist is literally sitting around with nothing to do, you may not get the copies back the same day.
3. Okay, I’ll scan them. Sure thing! Except that scanning and photocopying are usually two halves of the same coin, performed by the same person at the same copy service that charges per page and probably won’t get to it as fast as you’d like or need.
I’ve been in a couple of dozen archival collections and I’ve seen exactly one with a self-scanner. It was located outside of the special collections room where the material I wanted to scan was kept, and I wasn’t allowed to take the material outside of the room.
4. Scanning has its own challenges. Also … even self-service scanning may not be free. There is a flatbed scanner at the Wellcome Collection in London, which is a research collection that I adore for its cheerful atmosphere, friendly and helpful staff, decently priced cafe with surprisingly good food, and bookstore that I can never get out of without dropping at least £20. In fact, I recommend that anyone passing through London whose research pertains in any way to science or medicine take a look (their catalog is online so you can see in advance what they have).
It is, in fact, the same flatbed scanner that my home university library has, with the same little port to plug in a USB device, and I was delighted to find this out became it meant I wouldn’t have to mess around and figure out how the machine works. I laid out my book, hit “scan” … and nothing happened.
That’s when I saw the little sign saying that there was a cost of £0.10 per scan.
In one of my few moments of actual frustration at Wellcome, I discovered that the cost of the scan has to be paid with a copy card, which can only be purchased in cash. American readers may not see the issue here, so let me clarify that the UK is well on its way to being an entirely cashless society. I had literally not been presented with a cash-only situation during my entire stay in the UK, save for the weekly food market behind Birkbeck College, which had huge signs at the entrance warning people and pointing them to the nearest cashpoint.
I had no cash on me, and as far as I was able to tell there wasn’t an ATM anywhere within the same block as the library. So … yeah.
So, how do I plan a workflow?
What it comes down to is this: you need to have a plan as to how you are going to capture the documents you want, store them securely, and annotate them (this is so, so important), and you need to be comfortable with both the hardware and software that you’ll be using before you leave the house for the first time.
Learning this all in the field wastes your time and money. Most of us are on some sort of research funds (I actually wasn’t–more about that in a future post), meaning that we need to produce while we’re there. Losing a day’s work because you took all of your photos at the wrong ISO and they came out so pixelated as to be unreadable is a risk you don’t want to run (even more if you don’t understand what I just said).
Plan your workflow by working backwards.
Start by asking yourself this question: when you are sitting at your computer writing your dissertation, how do you want to consult your documents? Are you envisioning them as multi-page PDFs with searchable text? As paper copies in front of you (as much as I just pooh-poohed the idea of photocopying, if that’s your thing and you have the funds to support it, go for it)? As something else?
I’ll stop asking you these questions and tell you my personal answer, but I want to emphasize again and again, as I have throughout this entire guide to grad school, that the most important thing is that you devise a system that feels natural to you and that you’re comfortable with. You don’t have to do it the way I did.
I wanted to have PDFs of the documents. I have to admit that I didn’t really think much more through it than that, which became something of an issue when I got to the British Archives and discovered that a file number could refer to a single piece of paper in a folio, or to two massive boxes bound together with twine. This is where creating bookmarks within PDFs became important.
The question for me then became how to capture the documents as digital images and get them into PDF form.
Camera, laptop, documents, iPad … check! Turns out this was a bad idea.
I originally did this using my digital camera–the British National Archives has camera mounts for stability–to capture images, which I then transferred to my laptop using Adobe Lightroom where I … you know what, I don’t even remember. I did this on a short research trip and the workflow of getting the images off my camera into Lightroom and thence into a PDF was so utterly cumbersome and time consuming that it literally took me three years to get everything processed.
See, I like to take photos and I know how to use Lightroom … for photos. As it turns out, I did not know the first thing about using Lightroom to create documents from photos.
This is why I insist that you try your workflow at home. Pull that copy of Harry Potter and the Goblet of Fire off the shelf and act like it’s a book you need to copy.
I wound up regrouping using a capture device I hadn’t taken seriously: my phone.
A friend pointed me in the direction of a scanner app — Scanner Pro (no, I don’t have this monetized) — that works on the iPhone. There are similar apps for Android and other platforms, and Office365 and I believe Google Docs are jumping into the fray with their own entries.
Scanner Pro isn’t free, but I realized it would pay for itself after about three archival boxes so what the heck.
What I like about it is this: it does a terrific job of capturing print documents, of deskewing them (meaning: if you take a photo of the document at an angle, or the document is crooked in some way, as it might be if it’s bound together, as the British documents are, you can draw a box and it kind of straightens it out; enough for government work anyway), of creating multi-page PDFs, of running OCR (optical character recognition, meaning that it looks for recognizable text within the image–this is what makes the document searchable), and–extremely importantly from my point of view–it uploads the documents to the cloud (Dropbox, Google Docs, and Box are all covered at least).
Hence, by the time I left the archive I would have already uploaded that day’s work into the cloud. Even if my phone got lifted on the tube ride home, I wouldn’t have lost my work.
Now, as I said–I have no vested financial interest in Scanner Pro and could not care less if that’s the app you choose to work with. The important thing is that you pick an app and work with it a bit so that you know how to use it pretty well before you set foot in an archive.
I would suggest that you try out a number of different types of documents in different formats–Goblet of Fire is a big, fat book, so you can see how your program deals with curvy pages. Also try single documents, big type, small type, and if your work is likely to involve images, try those too.
I do not find that Scanner Pro works great with images, but I didn’t have many to contend with and was just as likely to use the actual camera function on my phone for those.
Dealing with the files
Okay, so you now have a system to digitize images into files. Great!
Hey, where are you going? Our work here isn’t done.
In fact, what comes next is VITALLY important.
It’s also incredibly tedious and easy to let slip. Try not to let it.
So, now you have a bunch of digital files … now what?
If you’re like me, your hard drive starts to look like this after a while.
In case you were wondering, there are six hundred files in this folder.
Also in case you were wondering … those are not the original file names that I gave these. I retro-organized this folder almost a year after I collected these articles because I realized that I had no idea what any of them contained. (The format is YYYY-MM-DD because Windows keeps it in order by date that way).
So, first up: two other tools I used.
One is a PDF editor. Scanner Pro does a lot, but sometimes I need a little more boost. Or I needed to OCR a language other than English. Or I wanted to insert bookmarks, as I did with this copy (left) of the testimony to the Milner Commission in 1919, because the file I generated was over two hundred pages long.
Sometimes I leave little digital sticky notes in the documents. As long as it took me to learn how to work paperless, I did eventually master the skill because … did I mention there were six hundred files in that one folder alone?
For this task, I lit on PDF XChange Editor. I’m not linking to it here because they’ve changed the way they sell the software–when I first found it, the PDF Viewer and the PDF Editor were sold together for about half the cost of what they’re selling each individually for now.
If you’re with a university and have access to student pricing, compare with Adobe Acrobat or see if your university offers another solution.
When it came to putting it all together, I am a huge fan and devotee of Zotero, which I will link to because it’s free and fucking fantastic.
Zotero is your digital librarian. There’s a lot of training available online (free), and a lot of universities support it pretty well–it can take a bit to unlock all of the things it can do, but here is why I like it a lot.
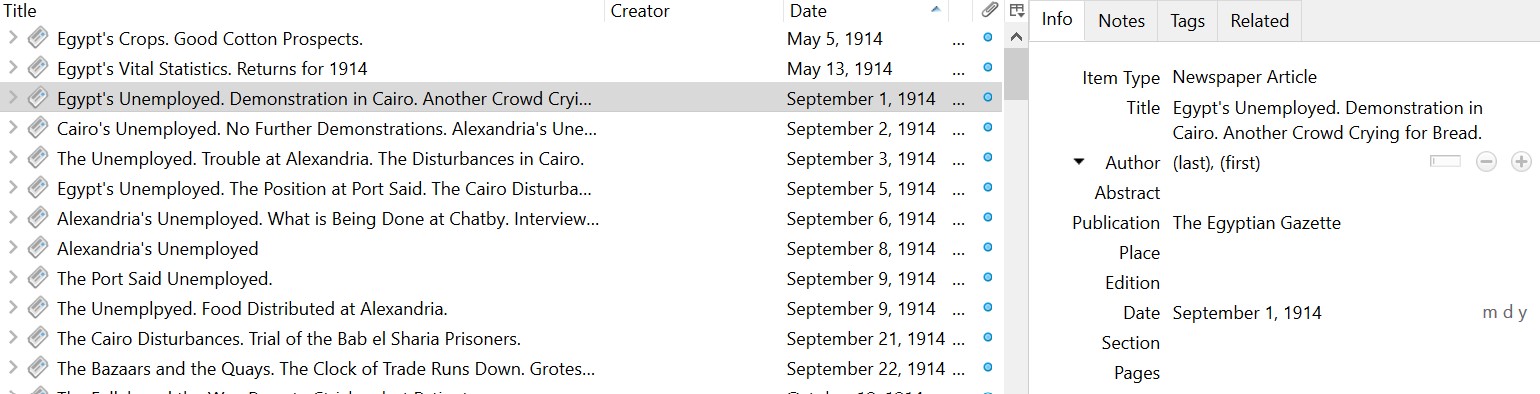
Here, for example, is what the Zotero version of the folder I posted above looks like:
I did have to go in and enter the title of each article, the author (if it had one), and date — this is something I would highly recommend that you get into the habit of doing daily. When I would come back to the flat I rented in London for my research stay, I would pour a glass of wine and sit in front of the TV and pick away at this on my laptop. If you let it go, it becomes unwieldy.
But here’s why this is useful. First off, you can include tags on each entry:
Now, if I want to find all of the articles from the Egyptian Gazette that have to do with unemployment demonstrations, I can find them.
Second … if you double click on the entry, it opens the PDF. (I use Box storage as my Zotero storage). It’s all linked right there.
Third, Zotero has plugins for Microsoft Office and OpenOffice (and other things–as it’s open source, people are constantly developing plugins) so that you can generate footnotes and endnotes without having to retype everything.
You can also import records into Zotero directly from your university library’s catalog — again, you don’t have to retype everything.
Seriously, given the number of people I know who had to spend days “fixing” their footnotes prior to submitting the dissertation, I cannot recommend Zotero enough.
But again, it has a learning curve.
Practice, Practice, Practice
This is my last piece of advice here, and it’s one I’ve said over and over: make sure you know how to use your tools. Make sure you’re comfortable with them. If something is a bit squidgy (academic term), google and see if there’s a workaround or how others have dealt with it.
You’ll have enough unanticipated issues to deal with on the road as it is. Having a solid plan as to how you’re going to work with the material you can collect from the beginning will take a lot of the stress off of your shoulders, so that when you get to the archives you can be productive right away.
In future columns on the research year, I’ll discuss how to plan out what you’ll be doing, and how to try to keep sane while you’re on the road. Stay tuned!